异构平台在线迁移
2022-09-06
为什么要迁移
mongodb 数据库定位
·OLTP/OLAP数据库
·原则上 Oracle 和 MySQL 能做的事情,MongoDB 都能做(包括 ACID 事务)
·优点:横向扩展能力,数据量或并发量增加时候架构可以自动扩展
·优点:灵活模型,适合迭代开发,数据模型多变场景
·优点:JSON 数据结构,适合微服务/ REST API
其实在功能上 mongodb已经具备了 像mysql数据库功能;但是如果想要迁移,特别是一些旧的业务迁移;就非常麻烦,业务,开发
从技术层面,mongodb做的是非常好的
基于功能选择mongodb
| mongodb | 关系型数据库 | |
|---|---|---|
| 亿级以上数据量 | 轻松支持(单节点即可,十亿百亿) | 要努力一下,分库分表 |
| 灵活表结构 | 轻松支持 | Entity Key / Value 表,关联查询比较痛苦 |
| 高并发读 | 轻松支持 | 需要优化 |
| 高并发写 | 轻松支持 | 需要优化 |
| 跨地区集群 | 轻松支持 | 需要定制方案 |
| 分片集群 | 轻松支持 | 需要中间件 |
| 地理位置查询 | 比较完整的地理位置 | PG还可以,其他数据库略麻烦 |
| 聚合计算 | 功能很强大 | 使用Group By等,能力有限 |
| 异构数据 | 轻松支持 | 使用EKV属性表 |
| 大宽表 | 轻松支持 | 性能受限 |
基于场景选择 MongoDB
迁移痛点
关系型到关系型一相对简单
·Oracle - MySQL, Oracle PostgresQL
关系型到文档型-相对复杂
·Oracle - MongoDB // 特别是代码层面,需要重构
需要考虑:
·总体架构(从单体式到分布式)
·模式设计(从关系模型到文档模型)
·SQL语句/存储过程/JDBC/ORM // 从 sql 转化为 mql
·数据迁移(如何处理已有数据?)
单点到分布式
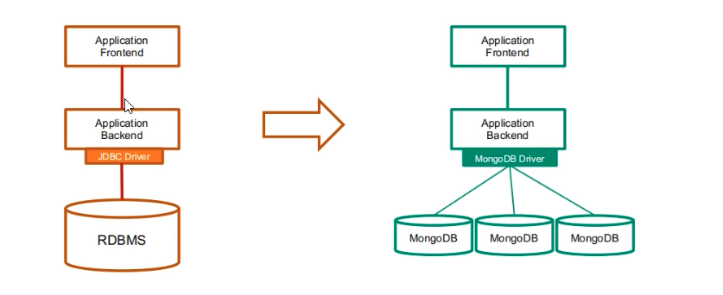
模式转换
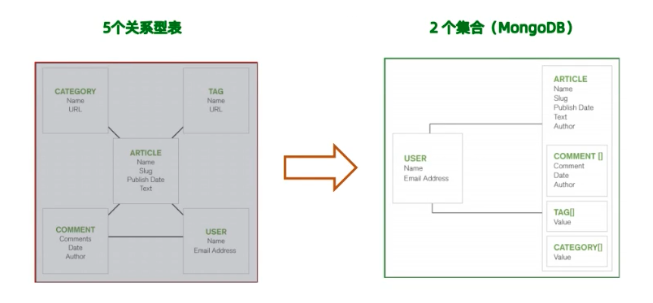
迁移主流程

RDBMS:
·存储过程
·运维工具、脚本
·权限设置
·数据库监控备份及恢复
Storage:
·典型的关系型数据库部署在 SAN 上
· MongoDB 支持 SAN,但是使用本地存储
·可以最大化的提高性能
JDBC:
MongoDB 没有原生态 JDBC,而是采用自带的驱动程序:
·自带连接池管理
·事务支持 SQL/RS:
MongoDB 不支持 SQL 的增删改,结果集也不是 ResultSet
等
DBA 主要关注 – 数据迁移
迁移方式
·数据库导出-导入
·批量迁移工具
·实时同步工具
·应用主导迁移 # 设置一个时间点,该时间点之后写入mongodb,改时间点之前的读操作去mysql,读完之后写入 mongodb;
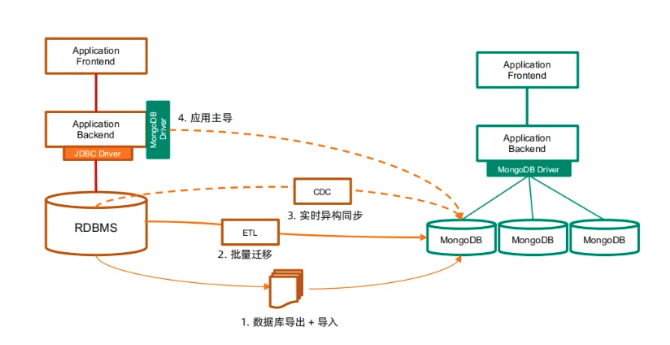
各种迁移方式的特点
1. 数据库导出导入
步骤:
-停止现有的基于 RDBMS 的应用
-使用 RDBMS 的数据库导出工具,将数据库表导出到 csv 或者 soN(如 mysqldump)一使用 mongoimport 将 CSV 或者 JSON 文件导入MongoDB 数据库
-启动新的 MongoDB 应用
备注:
-适用于一次性数据迁移
-需要应用/数据库下线,较长的下线时间
2. 批量同步
步骤:
-安装同步工具(如 Kettle/ Talend)创建输入源(关系型数据库)
-创建输出源(MongoDB) -编辑数据同步任务
-执行
备注:
-适用批量同步,定期更新,特别是每晚跑批的场景
-支持基于时间戳的增量同步,需要源表有合适的时间支持
-对源库有较明显的性能影响,不宜频繁查询
-不支持实时同步
3. 实时同步步骤:
-安装实时同步工具(如 Informatica/ Tapdata)
-创建输入源(关系型数据库)
-创建输出源(MongoDB)
-编辑实时数据同步任务
-执行
备注:
-基于源库的日志文件解析机制,可以实现秒级数据的同步
-对源库性能景影响较小
-可以支持应用的无缝迁移
4. 应用主导迁移
步骤:
1. 升级已有应用支持 MongoDB
2. 数据插入请求直接进入 MongoDB
3. 数据查询和更新请求首先定向到 MongoDB
4. 如果记录不存在,从 RDBMS 读出来并写入到 MongoDB
5. 重复步骤 3
6. 当步骤 4 在限定时间段(一星期、一个月)没有被调用,认为迁移完成
备注:
-需要研发团队配合,有一定开发和测试量
-为保证不遗漏数据,仍然先要执行一次批量同步
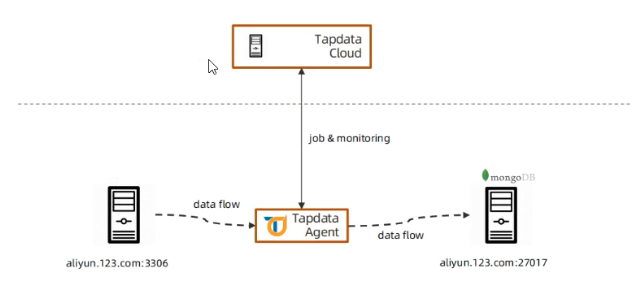
实时同步方案 – tpdata应用