redis 哨兵机制
哨兵机制
为什么要讲哨兵机制
A,我们学习了 redis 的主从复制,但如果说主节点出现问题不能提供服务,
需要人工重新把从节点设为主节点,还要通知我们的应用程序更新了主节点的地址,这 种处理方式不是科学的,耗时费事
B,同时主节点的写能力是单机的,能力能限
C,而且主节点是单机的,存储能力也有限
其中 2,3 的问题在后面 redis 集群课会讲,第 1 个问题我们用哨兵机制来解决
主从故障如何故障转移
A,主节点(master)故障,从节点 slave-1 端执行 slaveof no one 后变成新主节点
B,其它的节点成为新主节点的从节点,并从新节点复制数据
哨兵机制(sentinel)的高可用
A,原理:当主节点出现故障时,由 redis sentinel 自动完成故障发现和转移,并通知应用方,实现高可用性。
其实整个过程只需要一个哨兵节点来完成,首先使用 Raft 算法(感兴趣的同学可以查一下, 其实就是个选举算法)实现选举机制,选出一个哨兵节点来完成转移和通知;
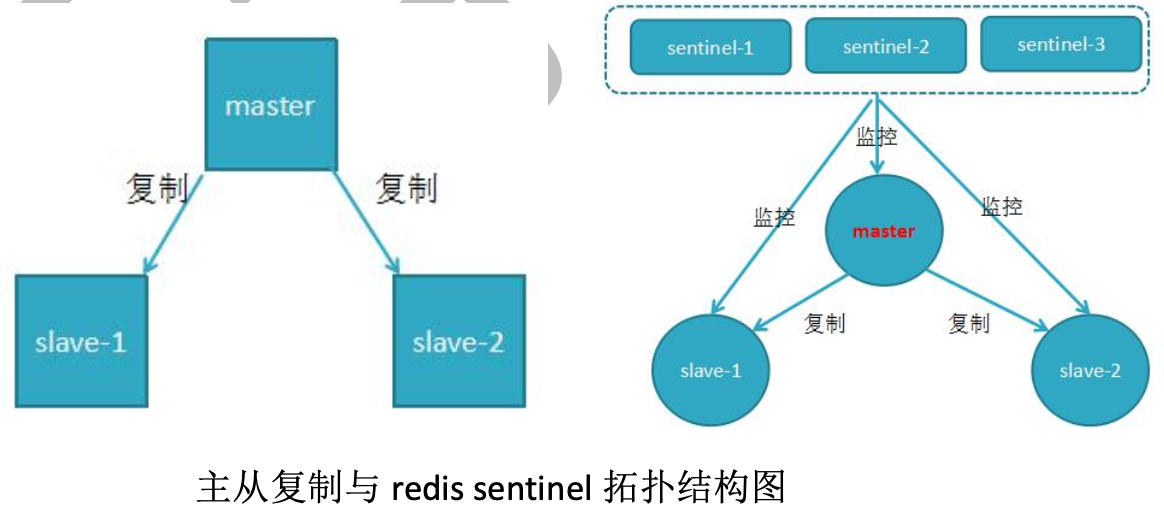
哨兵有三个定时监控任务完成对各节点的发现和监控
每个哨兵节点每 10 秒会向主节点和从节点发送 info 命令获取最拓扑结构图,哨兵配置时只要配置对主节点的监控即可,通过向主节点发送 info,获取从节点的信息,并当有新的从节点加入时可以马上感知到
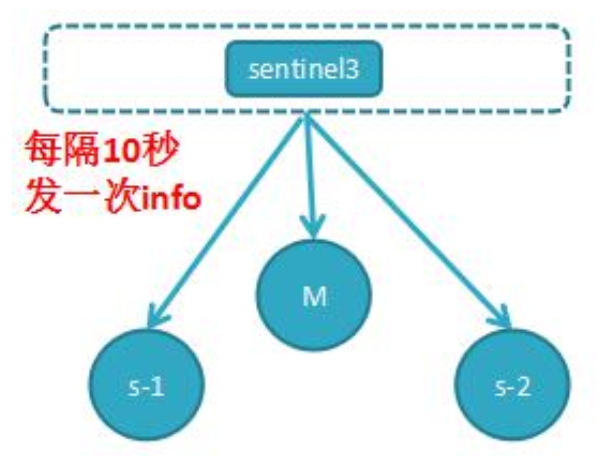
每个哨兵节点每隔 2 秒会向 redis 数据节点的指定频道上发送该哨兵节点对于主节点的判断以及当前哨兵节点的信息,同时每个哨兵节点也会订阅该频道,来了解其它哨兵节点的信息及对主节点的判断,其实就是通过消息 publish 和 subscribe 来完成的;
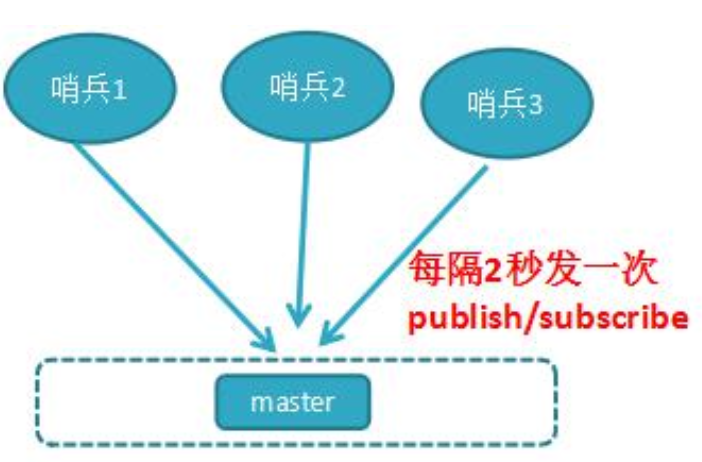
每隔 1 秒每个哨兵会向主节点、从节点及其余哨兵节点发送一次 ping 命令做一次心跳检测,这个也是哨兵用来判断节点是否正常的重要依据
主观下线和客观下线
主观下线:刚我知道知道哨兵节点每隔 1 秒对主节点和从节点、其它哨兵节点发送 ping做心跳检测,当这些心跳检测时间超过
down-after-milliseconds时,哨兵节点则认为该节点错误或下线,这叫主观下线;这可能会存在错误的判断。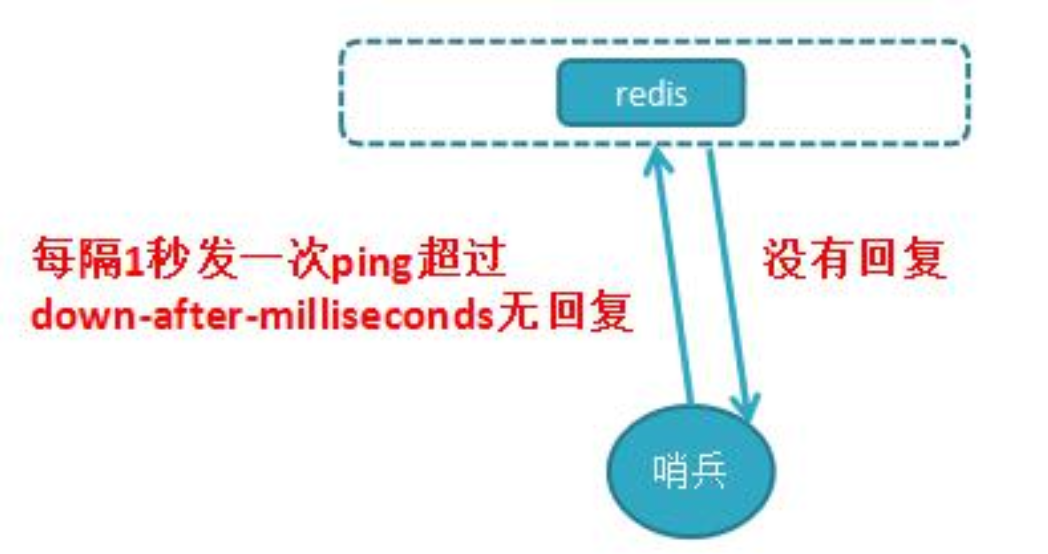
客观下线:当主观下线的节点是主节点时,此时该哨兵 3 节点会通过指令
sentinel is-masterdown-by-addr寻求其它哨兵节点对主节点的判断,当超过 quorum(法定人数)个数,此时哨兵节点则认为该主节点确实有问题,这样就客观下线了,大部分哨兵节点都同意 下线操作,也就说是客观下线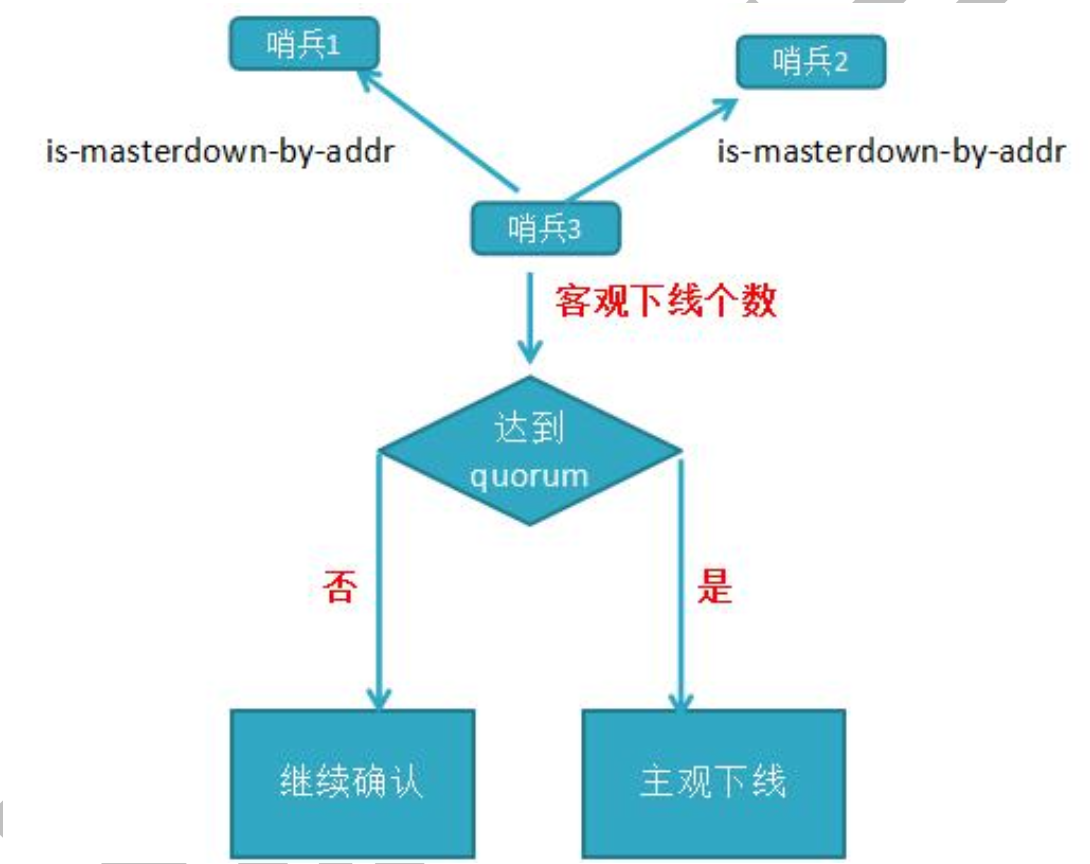
领导者哨兵选举流程
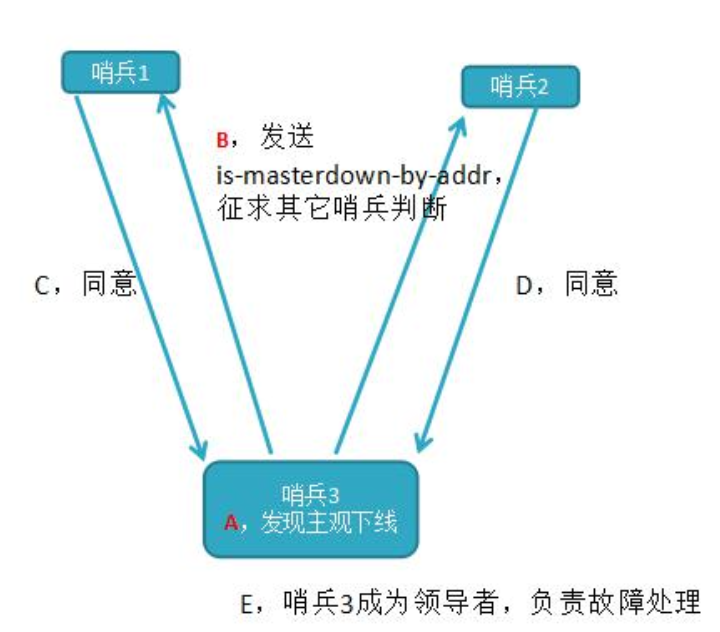
每个在线的哨兵节点都可以成为领导者,当它确认(比如哨兵 3)主节点下线时,会向其它哨兵发
is-master-down-by-addr命令,征求判断并要求将自己设置为领导者,由领导者处理故障转移;当其它哨兵收到此命令时,可以同意或者拒绝它成为领导者;
如果哨兵 3 发现自己在选举的票数大于等于 num(sentinels)/2+1 时,将成为领导者, 如果没有超过,继续选举............
故障转移机制
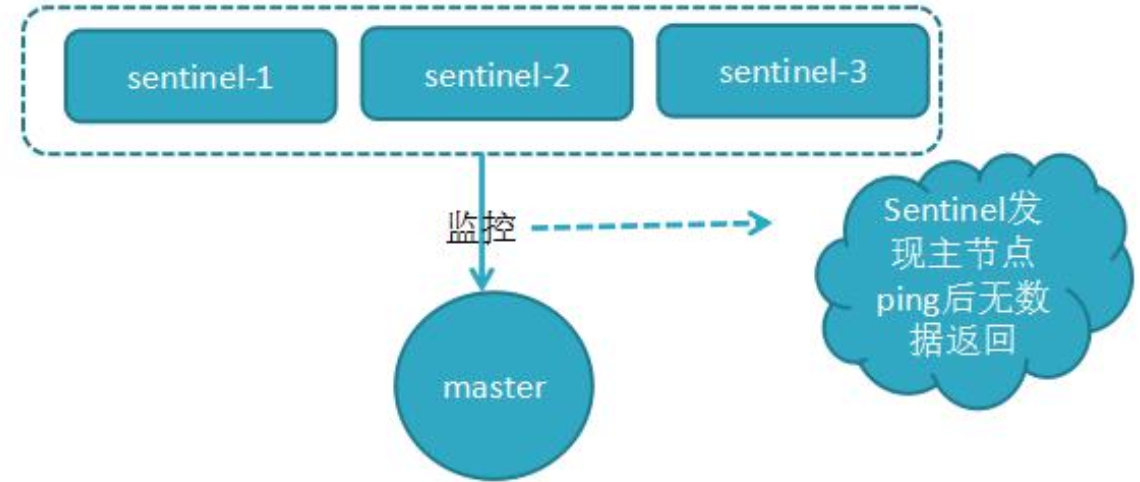
由 哨兵(Sentinel) 节点定期监控发现主节点是否出现了故障
sentinel 会向 master 发送心跳 PING 来确认 master 是否存活,如果 master 在“一定 时间范围”内不回应 PONG 或者是回复了一个错误消息,那么这个 sentinel 会主观地(单 方面地)认为这个 master 已经不可用了
当主节点出现故障,此时 3 个 Sentinel 节点共同选举了 Sentinel3 节点为领导, 负载处理主节点的故障转移
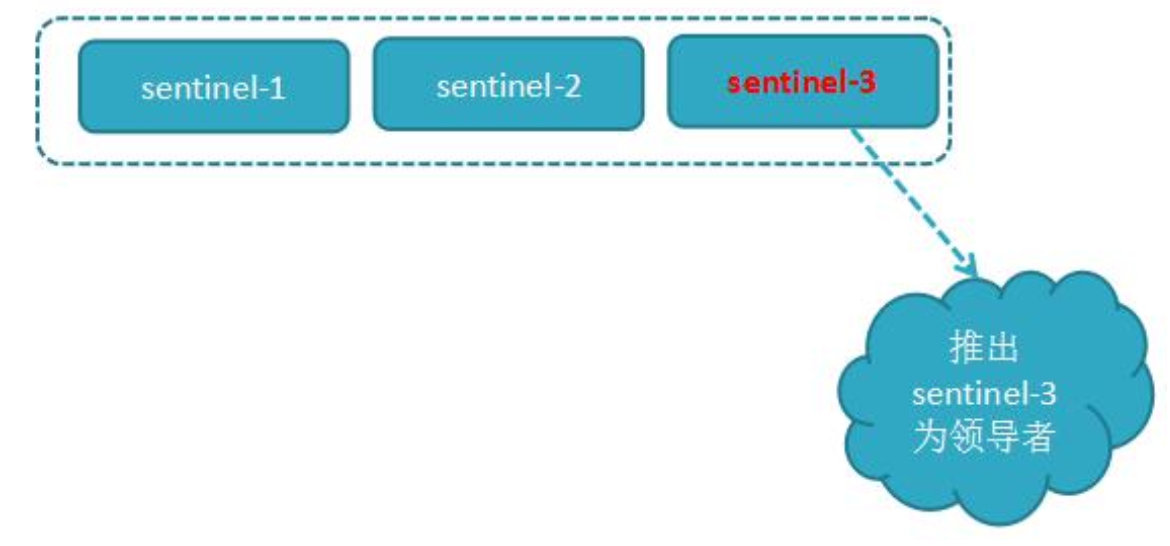
由 Sentinel3 领导者节点执行故障转移,过程和主从复制一样,但是自动执行
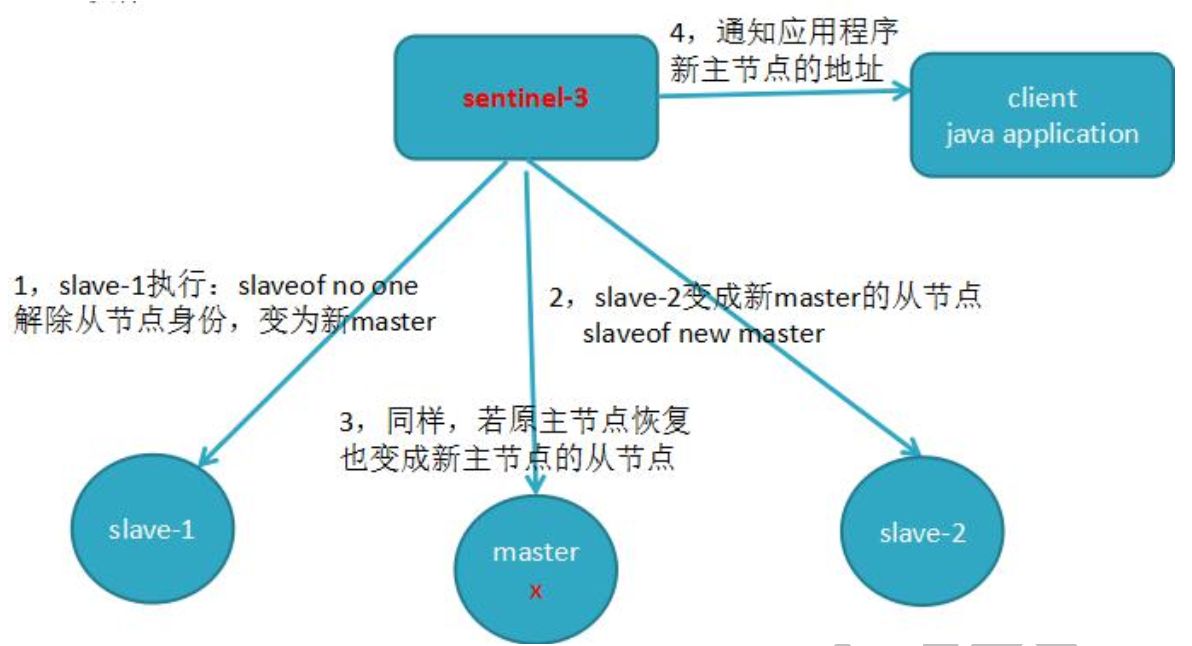
流程:
- 将 slave-1 脱离原从节点,升级主节点,
- 将从节点 slave-2 指向新的主节点
- 通知客户端主节点已更换
- 将原主节点(oldMaster)变成从节点,指向新的主节点
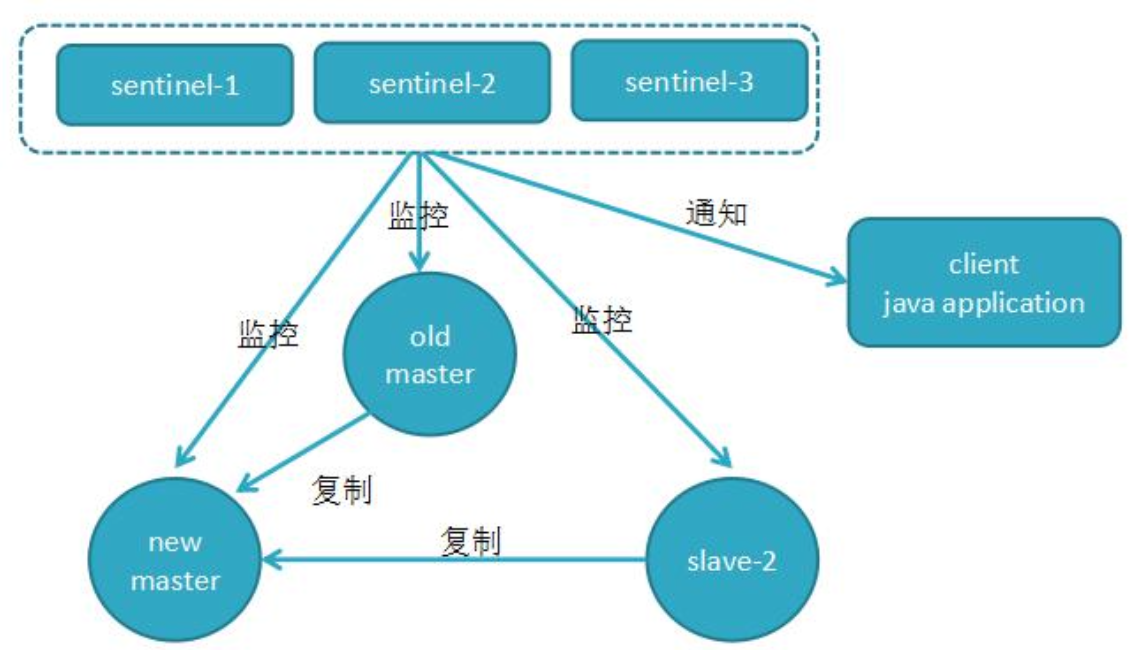
故障转移后的 redis sentinel 的拓扑结构图
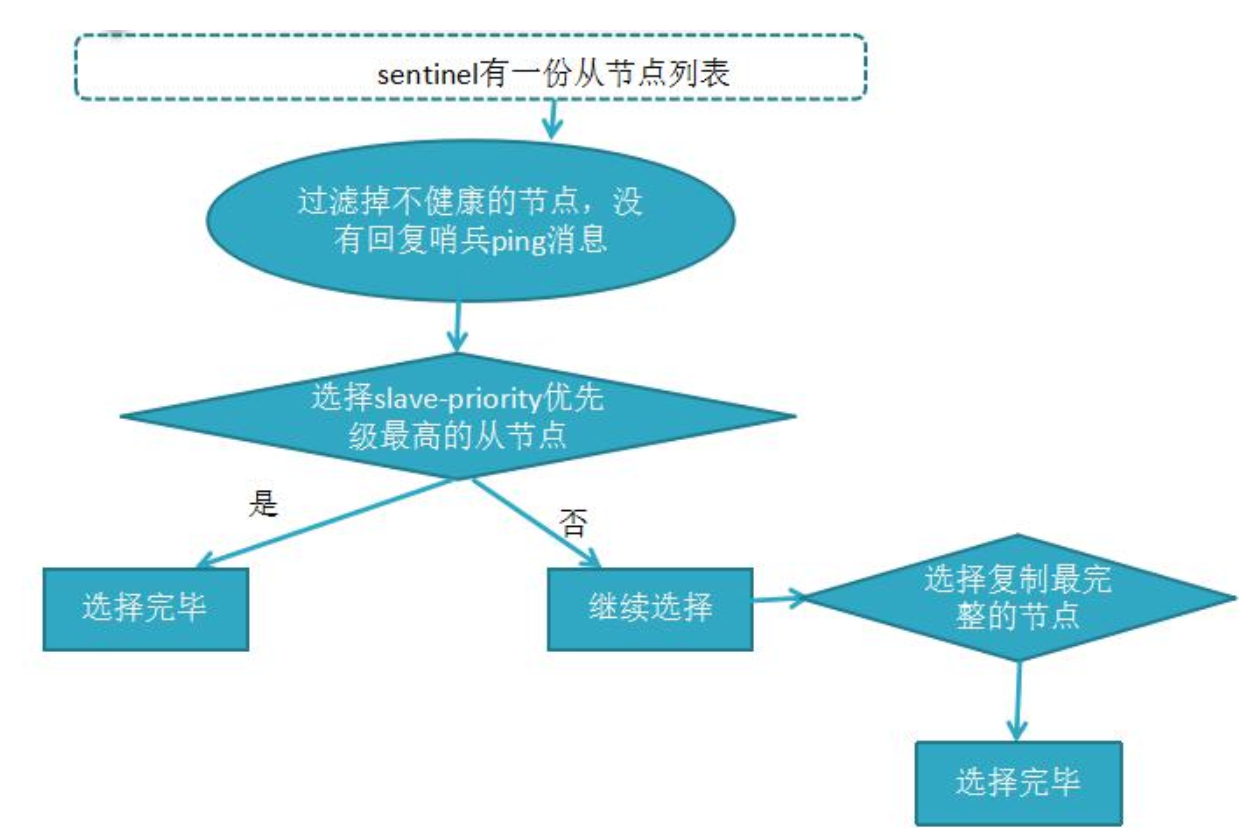
哨兵机制-故障转移详细流程
- 过滤掉不健康的(下线或断线),没有回复过哨兵 ping 响应的从节点
- 选择 slave-priority 从节点优先级最高(redis.conf)
- 选择复制偏移量最大,指复制最完整的从节点
- 最后重写 sentinel.conf 配置文件,以适应新场景的需要。同时 redis.conf 也会重写主从信息;
安装和部署 Reids Sentinel(哨兵)
以 3 个 Sentinel 节点、2 个从节点、1 个主节点为例进行安装部署
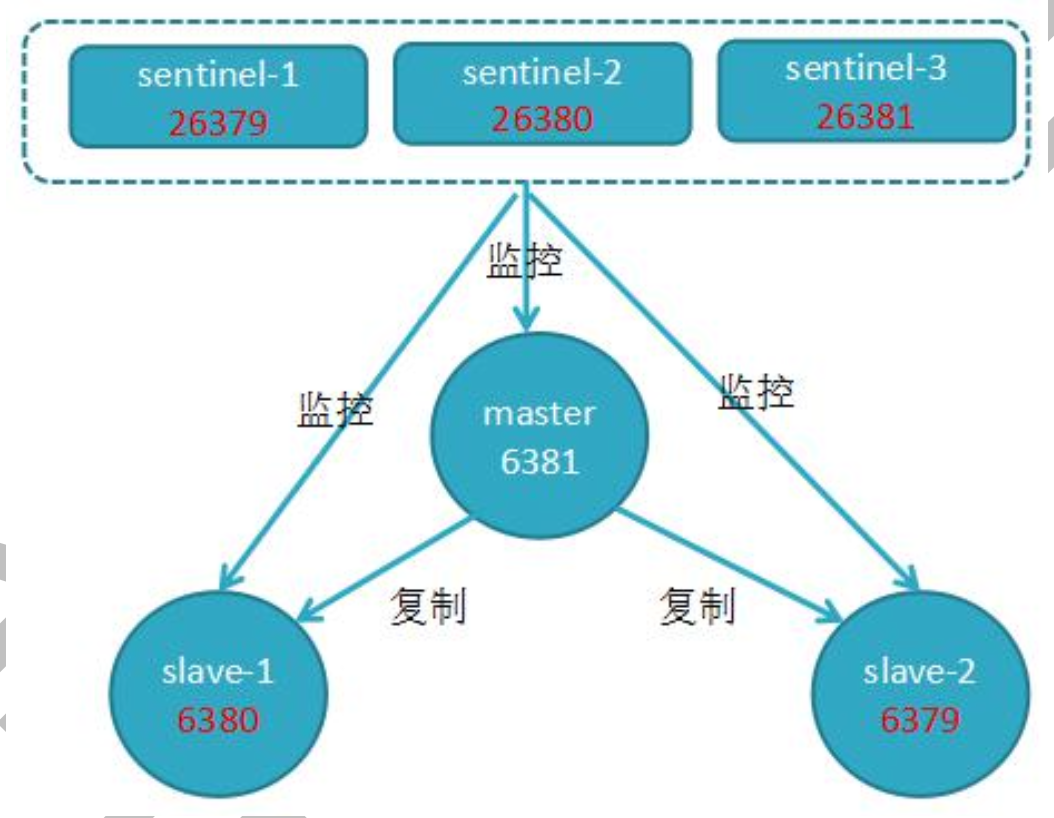
前提:先搭好一主两从 redis 的主从复制
和之前复制搭建一样,搭建方式如下:
主节点 6379 节点(
/opt/redis/redis.conf):# daemonize yes # 使得Redis服务器可以跨网络访问 bind 0.0.0.0 # 设置密码 requirepass "123456" # 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置 masterauth 123456从节点 redis6380.conf 和 redis6381.conf:
# daemonize yes # 使得Redis服务器可以跨网络访问 bind 0.0.0.0 # 设置密码 requirepass "123456" # 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置; ip地址为redis主的ip地址+端口 slaveof 192.168.11.128 6379 # 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置 masterauth 123456
注意:当主从起来后,主节点可读写,从节点只可读不可写
redis sentinel 哨兵机制核心配置(也是 3 个节点)
需要修改的地方如下:
/opt/redis/sentinel.conf
/opt/redis6380/sentinel.conf
/opt/redis6381/sentinel.conf
将三个文件的端口改成: 26379 26380 26381
# 然后 修改如下:
daemonize yes
dir ""
logfile "/opt/redis<Port>/logs/sentinel.log"
protected-mode no # 禁止保护模式
# sentinel monitor [master-name] [master-ip] [master-port] [quorum]
# 这里的[master-name]可以自定义,但涉及到[master-name]的参数都要相同
sentinel monitor mymaster 190.168.1.111 6379 2 # 监听主节点 6379
sentinel auth-pass mymaster 12345678 # 连接主节点时的密码 三个配置除端口外,其它一样。
# 最后启动 三个 sentinel
redis-sentinel /opt/redis/sentinel.conf
redis-sentinel /opt/redis6380/sentinel.conf
redis-sentinel /opt/redis6381/sentinel.conf
重要:sentinel monitor mymaster 192.168.42.111 6379 2 //切记将 IP 不要写成 127.0.0.1
不然使用 JedisSentinelPool 取 jedis 连接的时候会变成取 127.0.0.1 6379 的错误地址
哨兵其它的配置
// 监控主节点的 IP 地址端口,sentinel 监控的 master 的名字叫做 mymaster;2 代表,当集群中有 2 个 sentinel 认为 master 死了时,才能真正认为该 master已经不可用了
sentinel monitor mymaster 192.168.1.10 6379 2
sentinel auth-pass mymaster 12345678 //sentinel 连主节点的密码
sentinel config-epoch mymaster 2 //故障转移时最多可以有 2 从节点同时对新 主节点进行数据同步
sentinel leader-epoch mymaster 2
sentinel failover-timeout mymasterA 180000 //故障转移超时时间 180s,
a,如果转移超时失败,下次转移时时间为之前的 2 倍;
b,从节点变主节点时,从节点执行 slaveof no one 命令一直失败的话, 当时间超过 180S 时,则故障转移失败
c,从节点复制新主节点时间超过 180S 转移失败
sentinel down-after-milliseconds mymasterA 300000 //sentinel节点定期向主节点 ping 命令,当超过了 300S 时间后没有回复,可能就认定为此主节点出现故障了......
sentinel parallel-syncs mymasterA 1 //故障转移后,1 代表每个从节点按顺序排队一个一个复制主节点数据,如果为 3,指 3 个从节点同时并发复制主节点数据,不会影响阻塞,但存在网络和 IO 开销
客户端访问 哨兵集群的流程
哨兵服务器相当于注册中心。先从注册中心获取redis master 服务地址,然后再发起链接。当master宕机 哨兵会进行投票决定master是否真正死亡,然后选举最健康的slave作为新的master,然后客户端再次发起新的链接
RedisSentinel 监控 2 个 redis 主节点
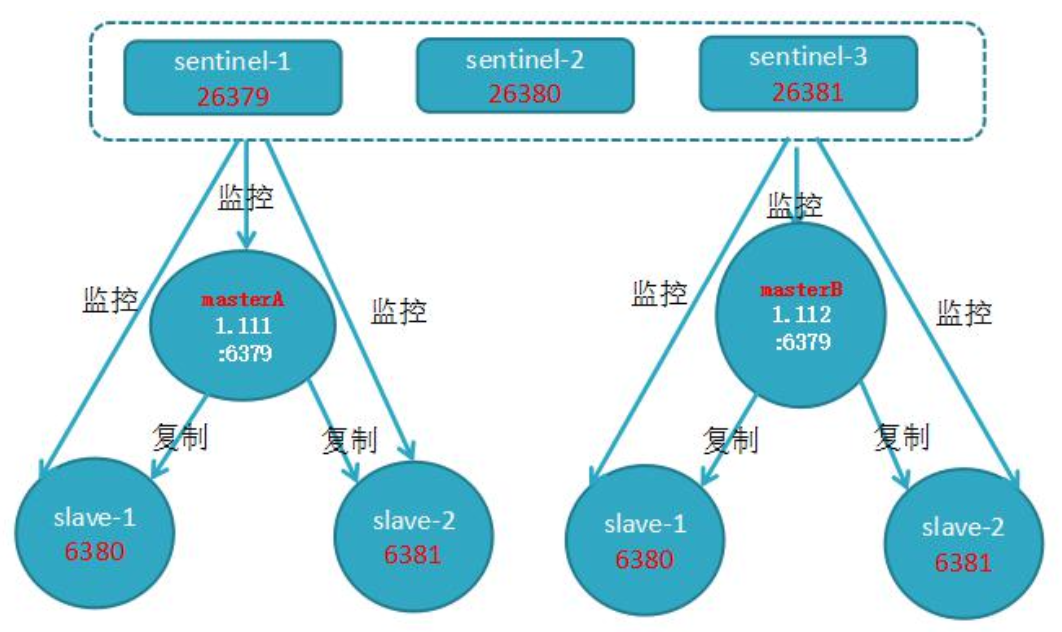
sentinel monitor mymasterB 192.168.1.20 6379 2
......其他配置与上面一样............。
部署建议
- sentinel 节点应部署在多台物理机(线上环境)
- 至少三个且奇数个 sentinel 节点
- 通过以上我们知道,3 个 sentinel 可同时监控一个主节点或多个主节点 监听 N 个主节点较多时,如果 sentinel 出现异常,会对多个主节点有影响,同时还会造成 sentinel 节点产生过多的网络连接, 一般线上建议还是, 3 个 sentinel 监听一个主节点
sentinel 哨兵的 API
命令:
redis-cli -p 26379 //进入哨兵的命令模式,使用 redis-cli 进入
26379>sentinel masters 或 sentinel master mymaster //查看 redis 主节点相关信息
26379>sentinel slaves mymaster //查看从节点状态与相关信息
26379>sentinel sentinels mymaster //查 sentinel 节点集合信息(不包括当前 26379)
26379>sentinel failover mymaster //对主节点强制故障转移,没和其它节点协商
Redis Sentinel 运维
<1> 更换主节点
执行以下命令:
sentinel failover <master-name>
# 例如
sentinel failover mymaster
如果想切换到指定的某台从节点上,那么需要先把其他的从节点的 priority 设置为0(设置为0,代表禁止该节点成为主节点),当切换成功后,再把其他从节点的 priority 复原即可。
<2> 增加 slave
在新加的 slave 的 redis.conf 文件中添加slaveof [master-ip] [master-port]的配置,使用redis-server 启动即可,它将被Sentinel节点自动发现。
<3> slave 下线
- 临时下线 临时下线只需要关闭某个从节点的redis服务即可。临时下线后,sentinel节点还是会监控这个已下线的从节点。
- 永久下线 永久下线首先关闭从节点的服务,然后让sentinel集群不再监控该节点。因为定期监控也会造成一定的网络资源浪费,sentinel更新监控节点的命令为:
sentinel reset master-name
<4> 增加 sentinel 节点
在新加的 sentinel 节点的 sentinel.conf 文件中设置sentinel monitor和其他配置,使用redis-sentinel启动即可,它将被其余sentinel节点自动发现。
<5> sentinel 节点下线
与 slave 下线一样,如果是临时下线,关闭服务即可。如果是永久下线,关闭服务后执行sentinel reset [master-name]命令。
注意事项
客户端连接(redis-sentinel 例子工程) 远程客户端连接时,要打开 protected-mode no