硬件优化
2022-08-27
1.1 关闭 numa
a.在bios层面,关闭numa;无论os层面的numa是否打开,都不会影响性能;
numactl --hardware
available: 1 nodes (0) 如果是2或者多个nodes就说明没有关闭numa
b.os grub 级别
vim /boot/grub2/grub.cfg
c.数据库级别
show variables like '%numa%';
或者:
vim /etc/init.d/mysqld
1.2 开启cpu高性能模式
1.3 阵列卡配置建议
raid10(推荐)
ssd 或者 pci-e 或者flash
强制回写(force writeback)
bbu 电池:如果没点会有较大性能影响、定期充放电,如果ups、多电路、发电机。可以关闭。
关闭预读
又肯呢个的话,开启cache(如果ups、多路电源、发电机)
1.4 关闭THP
vim /etc/rc.local
[root@master ~] cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
[root@master ~] cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never]
1.5 网卡绑定
bonding技术
建议使用主备模式
1.6 存储多路径
使用独立存储设备的话,需要配置多路径
linux自带:multipath
厂商提供
系统层面优化
a. 更改文件句柄和进程数
内核优化 /etc/sysctl.conf
vm.swappiness = 5 # swarp 使用
vm.dirty_ratio = 20
vm.dirty_background_ratio = 10
net.ipv4.tcp_max_syn_backlog = 819200
net.core.netdev_max_backlog = 400000
net.core.somaxconn = 4096
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 0
补充:
vm.dirty_ratio=20 -- 阻塞式刷新,强制刷新
vm.dirty_background_ratio = 10 -- 异步刷新,等待业务低谷时刷新
内存脏页/系统可用内存(free+BUF/ CACHE)
百分比达到比例,会刷脏页到磁盘。
=========================. 生产案例==========
监控显示内存 95%+
MySQL 实例:session mem (sort join read read rnd key heap table..) + shard mem (buffer pool \log buffer)
文件系统缓存---> binlog redo--> flush os cache---> sync
应急处理:
1. 文件系统:buff/ cache 20g ---> vm.dirty_ratio
2. 数据库:top 70g --- ckpt?
Innodb FLUSH METHOD = O_Direct
P_S 开的项目太低,会导致内存泄漏
=========================================
b. 防火墙
禁用 selinux: /etc/sysconfig/selinux 更改 SELINUX=disabled.
Iptables 如果不使用可以关闭。可是需要打开 MySQL 需要的端口号
c. 文件系统优化推荐使用 XFS 文件系统
MySQL数据分区独立,例如挂载点为:/data
mount 参数 defaults, noatime, nodiratime, nobarrier 如/etc/fstab:
/dev/sdb /data xfs defaults,noatime,nodiratime,nobarrier 1 2 # 这里不推荐检查磁盘,1 2 可以直接设置为 0 0
d. 不用lvm
e. io调用
SAS:deadline
SSD&PCI-E: noop
centos7 默认是 deadline
cat /sys/block/sda/queue/scheduler
#临时修改为 deadline (centos6)
echo deadline>/sys/block/sda/queue/scheduler
vi /boot/grub/grub.conf 更改到如下内容:
kernel /boot/vmlinuz-2.6.18-8.e15 ro root=LABEL=/ elevator=deadline rhgb quiet
补充:系统资源诊断 top
# 首先查看 mysql 的进程id;1380
[root@centos7 ~]# netstat -lnpt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 980/sshd
tcp6 0 0 :::3306 :::* LISTEN 1380/mysqld
# 使用top查看mysql具体哪个线程占用的cpu高
[root@centos7 ~]# top -Hp 1380
top - 15:01:52 up 1 day, 6 min, 1 user, load average: 0.04, 0.07, 0.01
Threads: 28 total, 0 running, 28 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 727160 total, 72620 free, 385308 used, 269232 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 238396 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1380 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.17 mysqld
1381 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
1382 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
1383 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
1384 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
1385 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
1386 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
1387 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
1388 mysql 20 0 1550516 185648 4752 S 0.0 25.5 0:00.00 mysqld
# 这里假设是 1382 占用的cpu高,
# 接下来就去mysql内部查看该线程在做什么
[root@centos7 ~]# mysql -u root -ppassword -S /mysql/3306/mysql.sock
# 进入虚拟库
mysql> use performance_schema;
# 查看具体该线程是干啥的;
mysql> select NAME,TYPE,THREAD_OS_ID from threads where THREAD_OS_ID=1382;
+------------------------------+------------+--------------+
| NAME | TYPE | THREAD_OS_ID |
+------------------------------+------------+--------------+
| thread/innodb/io_ibuf_thread | BACKGROUND | 1382 |
+------------------------------+------------+--------------+
1 row in set (0.00 sec)
# 然后根据该线程来进行优化mysql;
2、如果是系统的io占用高;
mysql> use sys;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-----------------------------------------------+
| Tables_in_sys |
+-----------------------------------------------+
| ... |
| io_by_thread_by_latency |
| io_global_by_file_by_bytes |
| io_global_by_file_by_latency |
| io_global_by_wait_by_bytes |
| io_global_by_wait_by_latency |
| ... |
# 这是 io 对应的表
# 查看 io 占用比较多的表的排名
mysql> select * from io_global_by_file_by_bytes;
+---------------------------------------------------------------------------------------+------------+------------+------------+-------------+---------------+------------+------------+-----------+
| file | count_read | total_read | avg_read | count_write | total_written | avg_write | total | write_pct |
+---------------------------------------------------------------------------------------+------------+------------+------------+-------------+---------------+------------+------------+-----------+
| @@datadir/ibtmp1 | 0 | 0 bytes | 0 bytes | 54 | 12.66 MiB | 240.00 KiB | 12.66 MiB | 100.00 |
| @@datadir/ibdata1 | 155 | 4.44 MiB | 29.32 KiB | 3 | 64.00 KiB | 21.33 KiB | 4.50 MiB | 1.39 |
| @@datadir/mysql/help_topic.ibd | 11 | 176.00 KiB | 16.00 KiB | 0 | 0 bytes | 0 bytes | 176.00 KiB | 0.00 |
| @@datadir/mysql/help_category.ibd | 5 | 80.00 KiB | 16.00 KiB | 0 | 0 bytes | 0 bytes | 80.00 KiB | 0.00 |
| @@datadir/sys/sys_config.ibd | 5 | 80.00 KiB | 16.00 KiB | 0 | 0 bytes | 0 bytes | 80.00 KiB | 0.00 |
| @@basedir/share/english/errmsg.sys | 3 | 76.58 KiB | 25.53 KiB | 0 | 0 bytes | 0 bytes | 76.58 KiB | 0.00 |
CPU 高怎么排查:
常规方法:
TOP -- PID---> 10
top -Hp 10 ---> TID -->110
select * from performance_ schema.threads where thread_os_id=110; --》thread_id 999,processlist id;
select * from per formance_schema.events_statements_history where thread_id=999;
经验方法:
show processlist; --- processist_id
select * from information_schema.processlist;
select * from performance_schema.threads where processist_id = 110;
select * from performance_schema.events_statements_history where thread_id=999;
内存:
RSS anno page cache buffer (mysql + fs cache)
3.数据库版本选择
基本上只调整内存参数,mysql8.0 会比 mysq 5.7 高个 2.5 倍以上
建议使用最新的版本;但是开发可能不太想用,可能需要优化一个
1、稳定版:选择开源的社区版的稳定版 GA 版本。
2、选择 mysq1 数据库 GA 版本发布后 6 个月-12 个月的 GA 双数版本,大约在 15-20 个小版本左右。
3、要选择前后几个月没有大的 BUG 修复的版本,而不是大量修复 BUG 的集中版本。
4、要考虑开发人员开发程序使用的版本是否兼容你选的版本。
5、作为内部开发测试数据库环境,跑大概 3-6 个月的时间。
6、优先企业非核心业务采用新版本的数据库 GA 版本软件。
7、向 BA 高手请教,或者在技术氛围好的群里和大家一起交流,使用真正的高手们用过的好用的 GA 版本产品。
最终建议:8.0.24 是一个不错的版本选择。向后可以选择双数版。
4.数据库三层结构及核心参数优化
4.1连接层
max_connections=1000 # 最大连接数,并发连接,不算本地连接;
max_connect_errors=999999 # 最大失败计数器;到了该数就不让连接了
wait_timeout=600 # 超时
interactive_wait_timeout=3600 #
net_read_timeout = 120 # 网络数据包延迟,
net_write_timeout = 120 #
max_allowed_packet= 32M # 最大数据包大小;备份的时候可能需要配置;
4.2 Server 层
sql_safe_updates =1 #
slow_query_log =ON
slow_query_log_file = /data/3307/slow.log
long_query_time =1
log_queries_not_using_indexes =ON
log_throttle_queries_not_using_indexes = 10
sort_buffer = 8M
join_buffer = 8M
read_buffer = 1M
read_rnd_buffer = 32M
tmp_table = 16M
heap_table = 16M
max_execution_time =28800 # mysql 8.0 默认已经不限制了;可以不用调整;
lock_wait_timeout =3600
lower_case_table_names =1 # 忽略大小写;
thread_cache_size =64
log_timestamps =SYSTEM
init_connect ="set names utf8mb4"
event_scheduler =OFF # 事件调度器
binlog_expire_logs_seconds =10 # binlog 保存时间,尽量保存一轮的全备周期
sync_binlog =1 # 刷新
log-bin =/data/3307/mysql-bin
log-bin-index =/data/3307/mysql-bin.index
max_binlog_size =500M
binlog_format =ROW
4.3 存储引擎层
Transaction-isolation ="READ-COMMITTED"
innodb_data_home_dir =/xxx
innodb_log_group_home_dir =/xxx
innodb_log_file_size =2048M # redo 日志
innodb_log_files_in_group =3 # 3 组 redo 日志
innodb_flush_log_at_trx_commit =2
innodb_flush_method =O_DIRECT # 对于数据刷新,是直接刷新到磁盘的;对于redo日志要先刷到缓存,再刷到磁盘;
innodb_io_capacity =1000 # ssd 盘,可以调整高一些;
innodb_io_capacity_max =4000 #
innodb_buffer_pool_size =64G # 一般50%
innodb_buffer_pool_instances =4 #
innodb_log_buffer_size =1024M # 根据日志文件配置
innodb_max_dirty_pages_pct =85
innodb_lock_wait_timeout =10 # 行锁
innodb_open_files =63000
innodb_page_cleaners =4
innodb_sort_buffer_size =64M # 排序缓冲区
innodb_print_all_deadlocks =1 # 死锁检测,一般打开
innodbrollback_on_timeout =ON # 8.0 默认打开
innodb_deadlock_detect =ON # 8.0 默认打开
4.4 复制
# 指定relay log 日志路径就是为了将 io 分开;数据文件存一个盘,relay log 存一个盘;
relay_log = /opt/log/mysql/blog/relay
relay_log_index = /opt/log/mysql/blog/relay.index
max_relay_log_size = 500M
relay_log_recovery = ON
rpl_semi_sync_master_enabled =ON
rpl_semi_sync_master_timeout =1000
rpl_semi_sync_master_trace_level =32
rpl_semi_sync_master_wait_forIslave_count =1
rpl_semi_sync_master_wait_no_slave =ON
rpl_semi_sync_master_wait_point =AFTER_SYNC # 启用 伴读 复制,5.7 增加的功能
rpl_semi_sync_slave_enabled =ON
rpl_semi_sync_slave_trace_level =32
binlog_group_commit_sync_delay = 1 # 每 1s 做一次批量的 gc
binlog_group_commit_sync_no_delay_count =1000 # 达到1000个也做gc,为了缓解单线程的问题
gtid_mode =ON
enforce_gtid_consistency =ON
skip-slave-start =1
#read_only =ON
#super_read_only =ON
log_slave_updates =ON
server_id =2330602
report_host =XXXX
report-port =3306
slave_parallel_type =LOGICAL_CLOCK # 多线程回放
slave_parallel_workers =4
master_info_repository =TABLE
relay_log_info_repository =TABLE
4.5 其他
客户端配置:
[mysq1]
no-auto-rehash # 客户端登录 每次 不扫描 文件,对文件句柄有缓解;加快登录速度
5.开发人员规范(优化人)
5.1字段规范
1. 每个表建议在 30 个字段以内。
2. 需要存储 emoji:字符的,则选择 utf8mb4 字符集。
3. 机密数据,加密后存储。 # 默认数据库也会有一个加密的功能,它是在引擎层次做的;
4. 整型数据,默认加上 UNSIGNED。
5. 存储 IPV4 地址建议用 INT UNSIGNE,查询时再利用 INET_ ATONO、INET_ NTOAO 函数转换。
6. 如果遇到 BLOB、TEXT 大字段单独存储表或者附件形式存储。
7 选择尽可能小的数据类型,用于节省磁盘和内存空间。
8 存储浮点数,可以放大倍数存储。 # 整数的过滤性能,比小数的过滤性能高很多;
9. 每个表必须有主键,INT/ BIGINT 并且自增做为主键,分布式架构使用 sequence,序列生成器保存。
10. 每个列使用 not nu11, 或增加默认值。
5.2 SQL 语句规范
参考:
https://dev.Mysql.com/doc/refman/8.0/en/optimization.html
### 1. 去掉不必要的括号
如: ((a AND b) AND c OR (((a AND b) AND (c AND d))))
修改成 (a AND b AND c) OR (a AND b AND c AND d)
###2. 去掉重叠条件
如: (a <b AND b=c) AND a=5
修改成 b>5 AND b=c AND a=5
如: (B> =5 AND B=5) OR (B=6 AND 5=5) OR (B=7 AND 5=6)
修改成 B=5 OR B=6
###3. 避免使用 not in、not exists、<>、1ike %%
select a.id, a.name
from
a where a.id not in (select b.id from b where b.coll='xx')
select a.id, a.name from a
left join b on a.id=b.id
where b.id is null and b.col1='xx';
### 4. 多表连接,小表驱动大表
### 5. 减少临时表应用,优化 order by、group by、union、distinct、join 等
### 6. 减少语句查询范围,精确查询条件
### 7. 多条件,符合联合索引最左原则
### 8. 查询条件减少使用函数、拼接字符等条件、条件隐式转换
### 9. Union a11 替代 union
### 10. 减少 having 子句使用
### 11. 如非必须不使用 for update 语句
### 12. Update 和 delete,开启安全更新参数
### 13. 减少 inset... Se1ect 语句应用
### 14. 使用 1oad 替代 insert 录入大数据
### 15. 导入大量数据时,可以禁用索引、增大缓冲区、增大 redo 文件和 buffer、关闭 autocommit、RC 级别可以提高效率
### 16. 优化 1imit,最好业务逻辑中先获取主键 ID,再基于 ID 进行查询
limit 5000000,10
### 17.DDL 执行前要审核
### 18. 多表连接语句执行前要看执行计划
6. 索引优化
1. 非唯一索引按照“_字段名称_字段名称【_字段名】”进行命名。
2. 唯一索引按照“u_字段名称_字段名称【_字段名】”进行命名。
3. 索引名称使用小写。
4. 索引中的字段数不超过 5 个。
5. 唯一键由 3 个以下字段组成,并且字段都是整形时,使用唯一键作为主键。
6. 没有唯一键或者唯一键不符合 5 中的条件时,使用自增 id 作为主键。7. 唯一键不和主键重复。
8. 索引选择度高的列作为联合索引最左条件
9. ORDER BY, GROUP BY, DISTINCT 的字段需要添加在索引的后面。
10. 单张表的索引数量控制在 5 个以内,若单张表多个字段在查询需求上都要单独用到索引,需要经过 BA 评估。查询性能问
题无法解决的,应从产品设计上进行重构。
11. 使用 EXPLAIN 判断 sQL 语句是否合理使用索引,尽量避免 extra 列出现:Using Fi e Sort, Using Temporary。12. UPDATE、DELETE 语句需要根据 WHERE 条件添加索引。
12, UPDATE、DELETE 语句需要根据 WHERE 条件添加索引。
13. 对长度大于 50 的 VARCHAR 字段 建立索引时,按需求恰当的使用前缀索引,或使用其他方法。
14. 下面的表增加一列 ur1_crc32, 然后对 ur1_crc32 建立索引,减少索引字段的长度,提高效率。
CREATE TABLE all_url(ID INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
url VARCHAR(255) NOT NULL DEFAULT 0,
url_crc32 INT UNSIGNED NOT NULL DEFAULT 0,
index idx_url(url_crc32));
15. 合理创建联合索引(避免元余),(a, b, c)相当于(a)、(a, b)、(a, b, c)。
具体可以查看sys库中的表;哪个表暂时忘了
16. 合理利用覆盖索引,减少回表。
17. 减少冗余索引和使用率较低的索引:sys 库
7. 锁优化
7.1 latch 闩锁(shuan suo)
A。介绍
latch 用于管理对共享内存资源的并发访问,例如,操作缓冲池汇总的 LRU 列表,删除、添加、移动 LRU 列表中的元素,为了保证一致性,必须有锁的介入,这就是 latch 锁。
b. latch 和 lock 的区别

c. 查看latch 争用的类型
mysql> show engine innodb mutex;
可以在 latch 争用较为严重情况下,定位到源码的位置点,从而获得到底什么原因导致争用。
也可以在此时通过以下工具分析堆栈信息:找堆栈中堵塞的函数;
pstack -p `pidof mysqld` >/tmp/aa.txt
pt-pmp /tmp/aa.txt | more
d. 什么时候发生争用
1) a 访问 x 内存链表
2) b 排队等待 x 解锁,占了 cpu,但是 cpu 发现你在等待,所以 cpu 将 b 踢出
3) 访问锁链的时间,就是找数据的时间。
4) b 知道很 a 快所以,b 不去排队,这时去 spin 也就是空转 cpu,然后再去看一下内存数据结构,a 是否已解锁
5) b 转了一圈后,在 b spin 的时间段的时间中,c 进来了,连续多次的 spin 后,产生了 os waits
6) 操作系统将 b 从 cpu 中踢出
latch 争用的表面现象:latch 争用会表现为 cpu 繁忙,Io 很闲,没有做实际的事情。
sys us 高,然后 Io 低
e. 如何监控是否latach争用较为严重
SEMAPHORES
OS WAIT ARRAY INFO: reservation count 13
OS WAIT ARRAY INFO: signal count 13
RW-shared spins 0, rounds 0, os waits 0
RW-excl spins 2, rounds 60, oS waits 2
RW-sx spins 2, rounds 60, oS waits 2
Spin rounds per wait: 0.00 RW-shared, 30.00 RW-excl, 30.00 RW-sx
rounds: 意思是每次询问旋转的次数
os waits: 表示 sleep,当突然增长比较快的时候,说明 1atch 争用比较严重
rw-shared spin 的次数
rw-excl spin 的次数
waits/rounds 超过 5%,要重视一下了。
诊断方法:
show engine innodb mutex; --》找源码
pstack -p `pidof mysqld` > /tmp/aa.txt
pt-pmp /tmp/aa.txt | more
f. latch 争用发生的原因
1、内存访问太频繁(不停地找)
2、1ist 链太长(链上挂 10000 个快,被持有的几率太大)
g. 如何降低latch 争用
如果出现 latch 争用比较严重
1. 优化大 sql, 降低对内存读的数量--效果比较明显
2. 增加 instances 的数量
7.2 全局锁(GRL global read lock)
a. 介绍
全局读锁。
加锁方法:FTWRL, flush tables with read lock。
解锁方法:unlock tables;
出现场景:
mysqldump --master-data=2
1. 记录 binlog--》不让所有事务提交
2. FTWRL ---》不让新的修改进入 --- show create database show create tables
3. Unlock tables
4. Snapshot innodb (-- single- transaction) ---》可以允许所有 DML,但是不允许 DDL
xtrabackup (8.0 之前早期版本)等备份时。
备份非 InnoDB:表数据时,FTWRL, unlock tables
备份 InnoDB 时,会 checkpoint 备份数据页。并记录 redo 变化,可以允许 DML,不允许 DDL
属于类型:MDL (matedatalock)层面锁
影响情况:加锁期间,阻塞所有事务写入,阻塞所有已有事务 commit。
MDL,等待时间受 lock_wait_timeout=31536000
b. 检测方法
UPDATE per formance_schema.setup_instruments
SET ENABLED='YES', TIMED ='YES'
WHERE NAME ='wait/lock/metadata/sq1/mdl';
mysql> select from per formance_schema.metadata_locks;
mysql> select OBJECT_SCHEMA, OBJECT_NAME LOCK_TYPE, LOCK_DURATION, LOCK_STATUS OWNER_THREAD_ID, OWNER_EVENT_ID from performance_schema.metadata_locks;
5.7 版本:
mysql> show processlist;
mysql> select from sys.schema_table_lock_waits;
c. 一个经典故障:5.7 xtrabackup/ mysqldump 备份时数据库出现 hang 状态,所有查询都不能进行
Session1: 模拟一个大的查询或事务
mysql> select *,sleep(100) from city where id <10 for update;
session2: 模拟备份时的 FTWRL
mysql> flush tables with read lock; -一此时发现命令被阻塞
session3: 发起正常查询,发现被阻塞
mysql> select from wor ld.city where id=1 for update;
结论:备份时,一定要选择业务不繁忙期间,否则有可能会阻塞正常业务。
案例 2:
5.7 innobackupex 备份全库,进程死了,mysql 里就是全库读锁,后边 insert 全阻塞了
7.3 Table lock
a. 介绍
表锁。
加锁方式:
lock table t1read。所有会话只读。属于 MDL 锁。
lock table write。当前持有会话可以 RW,其他会被阻塞。属于 MDL 锁
select for update
select for share
解锁方式:
unlock tables;
b. 检测方式
[mysqld]
performance-schema-instrument='wait/lock/metadata/sq1/mdl=ON'
mysql> select * from per formance_schema.metadata_locks;
mysql> select * from per formance_schema.threads;
7.4 MDL 锁
a. 介绍
Matedata lock 元数据锁。
作用范围:global、commit、tablespace、schema、table 等
默认 timeout 时间:1ock_wait_timeout
mysql> select @@lock_wait_timeout;
b. 监控
[mysqld]
performance-schema-instrument='wait/lock/metadata/sq1/mdl=ON'
mysql> select * from performance_schema.metadata_locks;
找到
OWNER_THREAD_ID: 62
mysql> select * from threads where thread_id='62'\G
PROCESSLIST_ID: 21
ki11 21;
7.5 autoinc_lock
自增锁。
通过参:innodb_autoinc_lock_mode=0,1
0: 表锁,每次插入都请求表锁,效率低。
1: mutex 方式,预计插入多少行,预申请自增序列。如果出现 load 或者 insert select 方式会退化为 0.
2: 强制使用 mutex 方式。并发插入可以更高效。
作用:
The default innodb_autoinc_lock_mode setting is now 2 (inter leaved). Inter leaved lock mode permits the execution of multi-row inserts in parallel, which improves concurrency and scalability.
7.6 innodb row lock
a. 介绍
record lock gap, next lock
都是基于索引加锁,与事务隔离级别有关。
b. 监控及分析
show status like 'innodb_row_lock%'
select * from information_schema.innodb_trx;
select * from sys.innodb_lock_waits;
select * from performance_schema.threads;
select * from performance_schema.events_statements_current;
select * from performance_schema.events_statements_history;
c. 优化方向
1. 优化索引
2. 减少事务的更新范围
3. RC
4. 拆分语句:
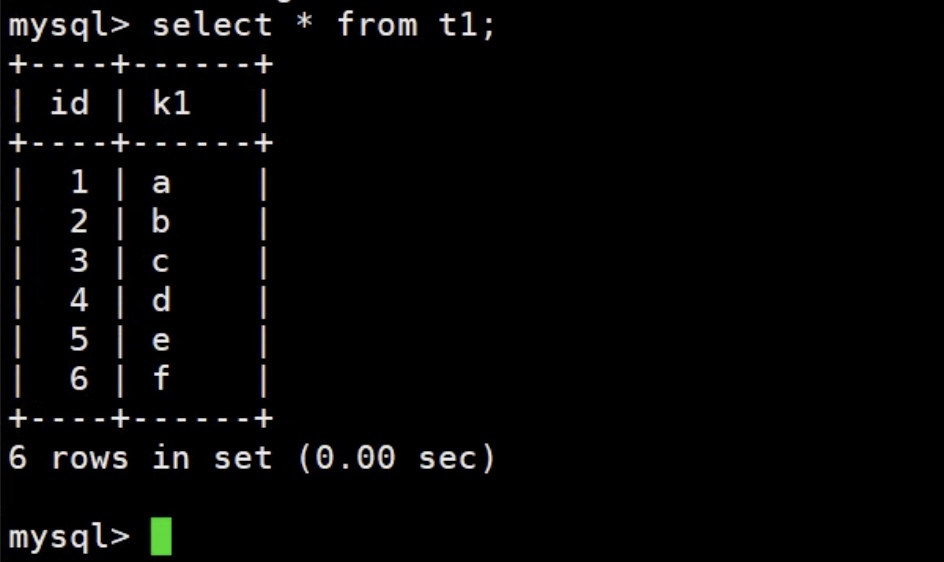
例如: update t1 set numa=num+10 where k1 < 100; k1 是辅助索引,record lock gap next
改为:
select id from t1 where k1 <100; ---> id: 20,30, 50
update t1 set num=num+10 where id in (20,30, 50);
7.7 死锁
a. 介绍
dead lock 多个并发事务之间发生交叉资源依赖时,会出现。
b. 监控及分析
show engine innodb status\G;
innodb_print_all_deadlocks =1 ---》将死锁记录到错误日志
c. 经典死锁案例延时及解析
8. 架构方面的优化
高可用架构:
keepalived+双主+GTID+增强半同步 # 增强半同步不可靠,需要对业务有一定容忍度;双主一般请款下只写一个主,有问题另一个主替换
MHA + ProxySQL+GTID+增强半同步 # 可以进行读写分离(proxysql),在主库宕机,从库顶上
xenon # 生成要提改 MHA;依赖 GTID + 增强半同步
orch+MHA
consul+zk..
RM
PXC # 可以达到 5个9 ,金融公司一般使用
MGR\InnoDB Cluster # 可以达到5个9,
读写分离:
ProxysQL, MySQL-router
分布式架构:
shardingsphere === sharding-jdbc proxy...
NoSQL: # 百万、千万级别的 流量进来;mysql 什么样的架构都吃力;借助 redis 分摊读压力
Redis+sentinel, Redis Cluster # 历史类的数据,查询比较多的,可以使用 mongo、es 来放数据,避免浪费mysql
MongoDB RS/MongoDB SHARDING Cluster
ES
第三代:new sql
NewSQL:
Pingcap TIDB (TUG)
TDSQL
PolarDB
OceanBase
第四代:HTAP
HTAP
9. 安全优化
1、使用普通 nologin 用户管理 MySQL
2、合理授权用户、密码复杂度及最小权限、系统表保证只有管理员用户可访问。
3、删除数据库匿名用户(5.6 及之前版本)
4、锁定非活动用户
5、MySQL 尽量不暴露互联网,需要暴露互联网,用户需要设置明确白名单、替换 MySQL 默认端口号、使用 ss1 连接
6、优化业务代码,防止 SQL 注入。
7、备份
8、sql 审核 --- 》 爱可生 在 1024 开源了产品
9、高可用及容灾
10. 常用工具介绍
一、PT (percona-toolkits)工具的应用:
pt-archiver
gh-ost
pt-table-checksum/sync
pt-kil1
pt-heartbeat
pt-show-grants
pt-query-digest
pt-summary
pt-pmp
1.pt工具安装
# [root@master ~] yum install -y percona-toolkit-3.1.0-2.el7.x86_64.rpm
# 官网地址 https://www.percona.com/downloads/percona-toolkit/LATEST/
# 安装 yum 仓库
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
# 安装
yum install percona-toolkit -y
2. 常用工具使用介绍
2.1 pt-archiver 归档表
场景:
需求:面试题:亿级的大表,delete:批量删除 100w 左右数据。 使用 pt-archiver 把这任务拆分;对业务影响最小;
面试题:定期按照时间范围,进行归档表。
#重要参数
--limit 100 每次取 1000 行数据用 pt- archiver:处理
--txn-size 100 设置 1000 行为一个事务提交一次
--where 'id <3000' 设置操作条件
--progress 5000 每处理 5000 行输出一次处理信息
--statistics 输出执行过程及最后的操作统计。(只要不加上-- quiet,默认情况下 pt- ar chiver 都会输出执行过程的)
--charset=UTF8 指定字符集为 UTF8-这个最后加上不然可能出现乱码。--bulk-delete 批量删除 source。上的旧数据(例如每次 1000 行的批量删除操作)
注意:需要归档表中至少有一个索引,做好是 where 条件列有索引
使用案例:1. 归档到数据库
db01 [test]> create table test1 like t100w;
# 从一个库归档表到另外一个库;不删除源数据, limit 1000 每次1000行,每1000行打印一次;
# 要求,原表要有索引,并且目标数据库中要有 该表;表结构相同;
# 该工具不能提高归档的速度,由于它可以拆分事务,可以给数据库不带来那么大的压力;10000 拆分为 10 x 1000
# --progress 1000 --statistics 每1000条显示一次
pt-archiver --source h=10.0.0.51,P=3307,D=test,t=t100w,u=root,p=123 --dest
h=10.0.0.51,P=3307,D=test,t=test1,u=root,p=123 --where 'id<10000' --no-check-charset --no-delete --limit=1000 --commit-each --progress 1000 --statistics
2. 只清理数据;--purge 删除符合条件的数据;limit 100 ,每100行切一次
# 删除也不会加快速度,由于拆分了,可以减少业务的影响;
pt-archiver --source h=10.0.0. 51,P=3307,D=test,t=t100w,u=root,p=123 --where 'id <10000' --purge --limit=100 --no-check-charset --progress 1000 --statistics
3, 只把数据导出到外部文件,但是不删除源表里的据
# --where '1=1' 为全表导出
pt-archiver --source h=10.0.0.51, D=world,t=city,u=root,p=123 --where '1=1' --no-check-charset --no-delete --file="/tmp/archiver.csv"
2.2 pt-osc
场景:
修改表结构、索引创建删除
不能加快速度,但能减少业务影响(锁》。
面试题:
pt-osc 工作流程:
1、检查更改表是否有主键或唯一索引,是否有触发器
2、检查修改表的表结构,创建一个临时表,在新表上执行 ALTER TABLE 语句
create table bak like t1;
alter table bak add telnum char(11) not null;
3、在源表上创建三个触发器分别对于 INSERT UPDATE DELETE 操作
create trigger
a
b
c
4、从源表拷贝数据到临时表,在拷贝过程中,对源表的更新操作会写入到新建表中
insert into bak select * from t1
5、将临时表和源表 rename(需要元数据修改锁,需要短时间锁表)
6、删除源表和触发器,完成表结构的修改。
Pt-osc 工具限制
1、源表必须有主键或唯一索引,如果没有工具将停止工作
2、如果线上的复制环境过滤器操作过于复杂,工具将无法工作
3、如果开启复制延迟检查,但主从延迟时,工具将暂停数据拷贝工作
4、如果开启主服务器负载检查,但主服务器负载较高时,工具将暂停操作
5、当表使用外键时,如果未使用 --alter-foreign-keys-method 参数,工具将无法执行
6、只支持 Innodb 存储引蔡表,且要求服务器上有该表 1 倍以上的空闲空间
Pt-osc 之 alteri 语句限制
1、不需要包含 alter table 关键字,可以包含多个修改操作,使用逗号分开,如 "drop clolumn c1, add column c2 int"
2、不支持 renamei 语句来对表进行重命名操作
3、不支持对索引进行重命名操作
4、如果删除外键,需要对外键名加下划线,如删除外键 fk_uid,修改语句为 "DROP FOREIGN KEY_fk_uid"
Pt-osc 之命令模板
## --execute 表示执行
## --dry-run 表示只进行模拟测试
## 表名只能使用参数 t 来设置,没有长参数
pt-online-schema-change \
--host="127.0.0.1" \
-port=3358 \
--user="root"\
--password="root@root"\
--charset="utf8"\ -
-max-lag=10 \
--check-salve-lag='xx.xx.xx.xx'\
--recursion-method="hosts" \
--check-interval=2 \
--database="testdb1" \
t="tb001"\
--alter="add column c4 int"\
--execute
例子:
# 该功能不支持 mysql 8.0 版本的操作;
# 表需要有唯一主键并且不为空;
pt-online-schema-change --user=root --password=123 --host=10.0.0.51 --port=3307 --alter
"add column state int not null default 1" D=test,t=tes1 --print --execute
pt-online-schema-change --user=oldguo --password=123 --host=10.0.0.51 --alter "add index idx(num)" D=test,t=t100w --print --execute
2.3 pt-table-checksum
场景:校验主从数据一致性
条件:需要从库的io线程是好的;
过程:会先拿到主库的信息,然后去从库拿;都拿到之后,再做校验;
2.3.1 预备环境配置;他会把检验信息存储到 pt 库中(可以自定定义),所以先创建该库;
create database pt CHARACTER SET utf8:
创建用户 checksum 并授权
create user 'checksum'@'10.0.0. %' IDENTIFIED with mysql_native_password BY 'checksum';
GRANT ALL ON * TO 'checksum'@'10.0.0. %';
flush privileges;
从库设定 report 信息;修改mysql配置文件,在[mysqld]下增加report_host=10.0.0.51;report-por=3309
# 然后重启数据库,再登录查看
mysql> select @@report_host;
@@report_host
10.0.0.51
1 row in set (0.00 sec)
mysql> select @@report-port;
@@report_port
3309
1 row in set (0.00 sec)
2.3.2 参数:
--[no]check--replication-filters:是否检查复制的过滤器,默认是 yes,建议启用不检查模式。
--databases | -d:指定需要被检查的数据库,多个库之间可以用逗号分隔。
--[no]check-binlog-format:是否检查 binlog 文件的格式,默认值 yes。建议开启不检查。因为在默认的 row 格式下会出错。
--replicate:把 checksum 的信息写入到指定表中。
-replicate-check-only:只显示不同步信息
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=pt.checksums --create-replicate-table --databases=test --tables=t1 h=10.0.0.51,P=3307,u=checksum,p=checksum
2.4 pt-table-sync
# 根据检验信息,去修复我们的表;不同步的数据
主要参数介绍
--replicate:指定通过 pt-table-checksum 得到的表。
--databases:指定执行同步的数食据库。
--tables:指定执行同步的表,多个用逗号隔开。
--sync-to-master:指定一个 DSN,即从的 Ip,他会通过 show processlist 或 show slave status 去自动的找主。
h= :服务器地址,命令里有 2 个 ip,第一次出观的是 Master 的地址,第 2 次是 s1ave 的地址。
u=:帐号。
p=:密码。
--print:打印,但不执行命令。
--execute:执行命令。
# 打印修复命令
pt-table-sync --replicate=pt.checksums --databases test --tables t1
h=10.0.0.51,u=checksum,p=checksum,P=3307 h=10.0.0.51,u=checksum,p=checksum,P=3309 --print
# 执行修复命令
pt-table-sync --replicate=pt.checksums --databases test --tables t1
h=10.0.0.51,u=checksum,p=checksum,P=3307 h=10.0.0.51,u=checksum,p=checksum,P=3309 --execute
2.5 pt-duplicate-key-checker
# 检查有没有重复索引,新版本 mysql8.0 sys 数据库帮我们做了
pt-duplicate-key-checker --database=test h='10.0.0.51' --user=oldguo --password=123
2.6 pt-ki11 语句
场景:无法正常 k11 的连接。
常用参数说明
--daemonize 放在后台以守护进程的形式运行;
--interval 多久运行一次,单位可以是 s, m, h, d 等默认是 s-不加这个黑认是 5 秒
--victims 默认是 oldest,只杀最古老的查询。这是防止被查杀是不是真的长时间运行的查询,他们只是长期等待这种和匹配按时间查询,杀死一个时间最高值。
--all 杀掉所有满足的线程
--kill-query 只杀掉连接执行的语句,但是线程不会被终止
--print 打印满足条件的语句
--busy-time 批次查询已运行的时间超过这个时间的线程;
--idle-time 杀掉 sleep 空闲了多少时间的连接线程,必须在 --match-command sleepl 时才有效-也就是匹配使用
--match-command 匹配相关的语句。
----ignore-command 忽略相关的匹配。这两个搭配使用一定是 ignore-commandd 在前 match-command 在后,--match-db cdelzone 匹配哪个库
command 有:Query、sleep、Binlog Dump、Connect、Delayed insert、Execute, Fetch、Init DB、Kill, Prepare,Processlist, Quit, Reset stmt, Table Dump
例子:
##杀掉空闲链接s1eep5秒的sQL并把日志放到/home/pt-ki11,1og文件中
/usr/bin/pt-kill --user=用户名 --password=密码 --match-command sleep-idle-time 5 --victim all --interval 5 --kill --daemonize -S /tmp/mysql.sock --pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log
###查询 SELECT 超过 1 分钟
/usr/bin/pt-kill --user=用户名 --password=密码 --busy-time 60 --match-info "SELECT|select" --victim all --interval 5 --kill --daemonize -S /tmp/mysql.sock --pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log
# Kill 掉 select IFNUL. 语句开头的 SQL
pt-kill-user=用户名 --password=密码 --victims all-busy-time=0 --match-info="select IFNUL1.*" --interval 1 -S /tmp/mysqld.sock --kill --daemonize --pid=/tmp/ptkill.pid --print --log=/tmp/pt-kil1. Log
###kill 掉 state Locked
/usr/bin/pt-kil1--user=用户名 --password=密码 --victims all --match-state='Locked' --victim all --interval 5 --kill --daemonize -S /tmp/mysqld.sock --pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log
##kill 掉 a 库,web 为 10.0.0.11 的链接
pt-kill --user=用户名 --password=密码 --victims al1 --match-db='a' --match-host='10.0.0.11' --kill --daemonize --interval 10 -S /tmp/mysqld.sock --pid=/tmp/ptkill.pid --print-log=/tmp/pt-kill.log
##指定哪个用户 kill
pt-kill-user=用户名 --password=密码 --victims al1 --match-user='root' --kill --daemonize --interval 10 -S /home/zb/data/my6006/socket/mysqld.sock --pid=/tmp/ptki11.pid --print --log=/home/pt-kill.log
##kill 掉 command query | Execute
Pt-kill--user=用户名 --password=密码 --victims all --match-command="query|Execute" --interval 5 --kill --daemonize -S /tmp/mysqld.sock --pid=/tmp/ptkill.pid --print --log=/home/pt-kill.log
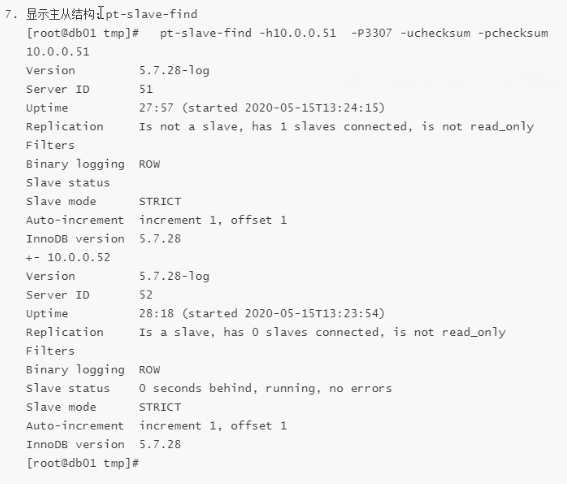
7. 显示主从结构:pt-slave--find
[root@db01 tmp] # pt-slave-find -h10.0.0.51 -P3307 -uchecksum -pchecksum
# 会打印主从的结构信息;
8. 监控主从延时
#pt-heartbeat
主库:主库会创建一个表,不断的往表里写数据,
pt-heartbeat --user=root --ask-pass --host=10.0.0.51 --port=3307 --create-table -D test --interval=1 --update --replace --daemonize
从库:从库会同步该表,并且检测同步的时间;延迟打印出来;
pt-heartbeat --user=root --ask-pass --host=10.0.0.51 --port=3309 -D test table=heartbeat --monitor
9. # pt-show-grants
作用:用户和权限信息迁移。比较好用,会把全新什么的都转换为sql语句。跨版本比较好用;
pt-show-grants -h10.0.0.51 -P3307 -uchecksum -pchecksum
# 自己扩展
pt-query-digest
pt-summary # 会采集系统信息;包括 top io 网卡信息都会采集出来,可以很好的帮助分析系统瓶颈
pt-pmp #
11. 压测
11.1 目的
a. 上线之前压测烤机,对硬件测试;cpu、io、网络、mem
b. 基准的获取:tps qps rt
c. 性能对比(参数、配置)
11.2 关注指标
cpu: user sys wait
mem: total freee used av buffer cache
IO :
await: 每次设备io操作的等待时间(毫秒)
svatm:平均的服务时间
%util:在1秒内用户io操作的时间百分比
DB:
TPS
QPS